How we fixed my SEO
· 35 min read

We might also call this:
I ruined my SEO and a stranger from Hacker News help me fix it
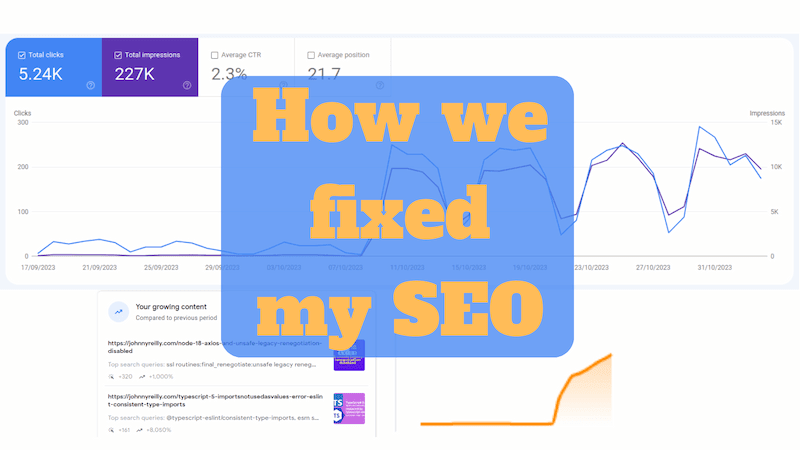
This is a follow up to my "How I ruined my SEO" post. That was about how my site stopped ranking in Google's search results around October 2022. This post is about how Growtika and I worked together to fix it.
As we'll see, the art of SEO (Search Engine Optimisation) is a mysterious one. We made a number of changes that we believe helped. All told, my site spent about a year out in the cold - barely surfacing in search results. But in October 2023 it started ranking again. And it's been ranking ever since.
I put that down to the assistance rendered by Growtika. What was the nature of that assistance? I'll tell you. This post is a biggie; so buckle up!